Transformer 统治的时代,为什么 LSTM 并没有被完全替代?
条评论LSTM 和 Transformer 都是当下主流的特征抽取结构,被应用到非常多的领域,各有它的擅长和优缺点。关于 LSTM 与 Transformer 结构的强弱争论,笔者认为还是要根据具体的研究领域进行讨论才有意义,毕竟目前很多模型改进的方向,其实就是改造使得它更匹配领域问题的特性。
本文基于时间序列上两种模型的具体实践,来聊聊 LSTM 这种 RNN 结构以及 Transformer 结构的实际差异与优劣,供大家参考。欢迎大家访问原文与我交流。
LSTM 为什么火?
RNN 的这种结构在某种程度上来讲,是在序列领域火起来的,为什么?主要原因还是因为RNN 的结构天然适配解决序列数据的问题,其输入往往是个不定长的线性序列句子,而 RNN本身结构就是个可以接纳不定长输入的由前向后进行信息线性传导的网络结构。更何况为了解决标准 RNN 的梯度爆炸和长程信息消失问题,诞生了 LSTM 这种引入三个门的结构,对于捕获长距离特征非常有效,也正是因为 RNN 特别适合线形序列应用场景,才使得它在序列研究领域如此流行的根本原因。
特别是在各种 Attention 注意力机制的加持下,几乎促使 RNN 在各个 SOTA 模型中频繁出没,通过叠加网络增加网络的深度,以及引入 Encoder-Decoder 框架,这些技术进展极大拓展了 RNN 的能力以及应用效果,比较典型的就是 Google NMT 了,结构如下:
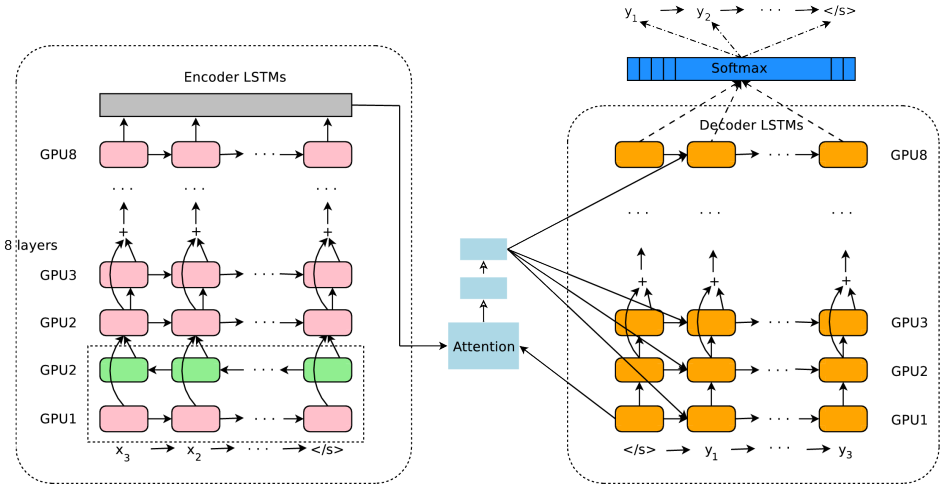
可以看到 NMT 的结构包含了双向 RNN、多层单向 RNN、注意力机制、Encoder-Decoder结构于一身,就是这样的结构才使得 NMT 的效果非常惊人。
LSTM 的痛点
慢!之前写过利用 LSTM 的 seq2seq 模型以及在 LAS 中使用,参数一大训练速度慢的不行,吐槽!相关模型可以参见 GitHub:
https://github.com/DengBoCong/nlp-paper
RNN 还有一个很明显的缺点,就是 RNN 本身的序列依赖结构对于大规模并行计算来说相当的不友好,换句话说,就是 RNN 很难具备高效的并行计算能力。深度学习大火的原因就是因为 GPU 硬件环境在支持,而 RNN 因为先天结构的问题(T 时刻的隐层状态 St 还依赖 T-1 时刻的隐层状态 St-1 的输出,这是最能体现RNN本质特征的一点),无法充分利用硬件的并行计算能力,这是一个非常非常大的问题!
反观 Transformer 就不存在这种序列依赖问题,所以对于这两者来说并行计算能力就不是问题,每个时间步的操作可以并行一起计算。
当然针对 RNN 结构的优化很多大牛都在研究,想方设法的改造 RNN 使其具备并行计算能力,主要是如下两种方式:
隐层单元之间的并行计算
这种方法的代表就是论文《Simple Recurrent Units for Highly Parallelizable Recurrence》 中提出的 SRU 方法,它最本质的改进是把多层 RNN 结构中,隐层之间的神经元依赖由全连接改成了哈达马乘积,这样 T 时刻隐层单元本来对 T-1 时刻所有隐层单元的依赖,改成了只是对 T-1 时刻对应单元的依赖,于是可以在隐层单元之间进行并行计算,但是收集信息仍然是按照时间序列来进行的。所以其并行性是在隐层单元之间发生的,而不是在不同时间步之间发生的。
用上面 Google NMT 中对 RNN 的优化方式来通俗的讲,就是多层 RNN 结构中,Encoder和 Decoder 的不同层的 LSTM 会在不同的 GPU 上运行,因为更上一层的 LSTM 不必等到下一层的神经网络完全计算完毕再开始工作。当然,上面这种方法的并行程度上限是有限的,并行程度取决于隐层神经元个数,而一般这个数值往往不会太大,再增加并行性已经不太可能。
切断时间步关联进行并行计算
这种方法的代表就是论文《Sliced Recurrent Neural Networks》中提到的 Sliced RNN,从它的名字上我们可以体会到,通过对时间步的切片来实现并行计算。为了能够在不同时间步输入之间进行并行计算,Sliced RNN 就是打断隐层之间的连接,但是又不全打断,因为这样基本就无法捕获组合特征了,所以它选的策略就是部分打断,比如每隔2个时间步打断一次。对于距离稍微远点的特征,通过加深层深来建立远距离特征之间的联系,Sliced 的结构和普通RNN 的结构进行对比如下:
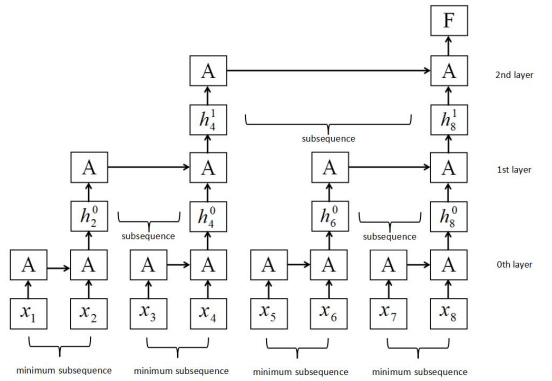
看起来真的有点 CNN 的味道了,这貌似都不是 RNN 了,论文中提到这种类似于 CNN 结构的 RNN 比 GRU 模型快 5-15 倍,但是比 CNN 模型还是慢了大约3倍。我个人认为,从某种程度上讲,这种结构都不能叫做真正的 RNN 了,毕竟 RNN 的根本特征就是线性序列之间的连接,Sliced RNN 无非是为了让它看上去还像是 RNN,所以在打断片段里仍然采取RNN 结构,这样无疑会拉慢速度,所以这是个两难的选择,与其这样不如直接换成其它模型。
**Transformer 优势
**
Transformer 的模型结构细节我在这里就不多赘述了,在深度学习中混的,就算没用过Transformer,听也听的耳朵长茧了,它的论文《Attention Is All You Need》能够满足你的所有幻想。Transformer 牛逼之处在于,使用 Self-attention 以及 Muli-head Self-attention 进行语义抽取(关于序列中长距离依赖特征的问题,Self attention 天然就能解决这个问题,因为在集成信息的时候,当前单词和句子中任意单词都发生了联系,所以一步到位就把这个事情做掉了),并通过正弦位置编码保留输入句子单词之间的相对位置信息,这一套组合拳一打出来,威力惊人。不像 RNN 需要通过隐层节点序列往后传,也不像 CNN 需要通过增加网络深度来捕获远距离特征,Transformer 在这点上明显方案是相对简单直观的。
Transformer 和 LSTM 选谁?
这个问题很难回答,就和最开始说的,根据特定的任务领域自行抉择,我这里针对几个关键点进行对比和比较,能够帮助你更好的选择,以下的数据和结论来源于论文《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》,论文中还带上了 CNN 一同进行对比,三个特征抽取模型:
语义特征提取能力
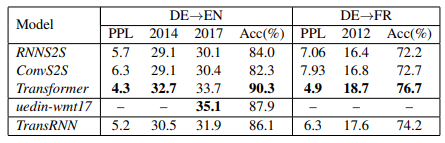
从实验中我们可以看出,Transformer 在这方面的能力非常显著地超过 RNN 和 CNN(在考察语义类能力的任务 WSD 中,Transformer 超过 RNN 和 CNN 大约 4-8 个绝对百分点),RNN 和 CNN 两者能力差不太多。
长距离特征捕获能力
CNN 特征抽取器在这方面极为显著地弱于 RNN 和 Transformer,Transformer 微弱优于RNN 模型(尤其在主语谓语距离小于13时),但在比较远的距离上(主语谓语距离大于13),RNN 微弱优于 Transformer,所以综合看,可以认为 Transformer 和 RNN 在这方面能力差不太多,而 CNN 则显著弱于前两者。
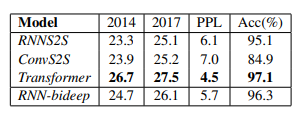
任务综合特征抽取能力
这里展示 GPT 论文中的实验数据:

从综合特征抽取能力角度衡量,Transformer 显著强于 RNN 和 CNN,而 RNN 和 CNN 的表现差不太多,如果一定要在这两者之间比较的话,通常 CNN 的表现要稍微好于 RNN 的效果。
并行计算能力及运行效率
这里展示论文《Tensor2Tensor for Neural Machine Translation 》中的数据:
self attention 的平方项是序列长度,因为每一个值都需要和任意一个值发生关系来计算 attention,所以包含一个 n 的平方项,而 RNN 和 CNN 的平方项则是 embedding size。当前常用的 embedding size 从 128 到 512 都常见,所以在大多数任务里面其实 self attention 计算效率是要高于 RNN 和 CNN 的。
总结
通过上述对比,是不是感觉 Transformer 真是个好东西?事实也证明 Transformer 确实在大部分场景下,是一个非常不错的选择,也正是 Transformer 的出现,打开了原本 RNN 占据的江山,现在还不能说LSTM(RNN)被替代,因为有着属于它自己的优势,比如长距离特征下的特征抽取,但是不得不承认现在的趋势已经向着 Transformer 的生态靠拢了。